OmniFusion
360 Monocular Depth Estimation via Geometry-Aware Fusion
Abstract
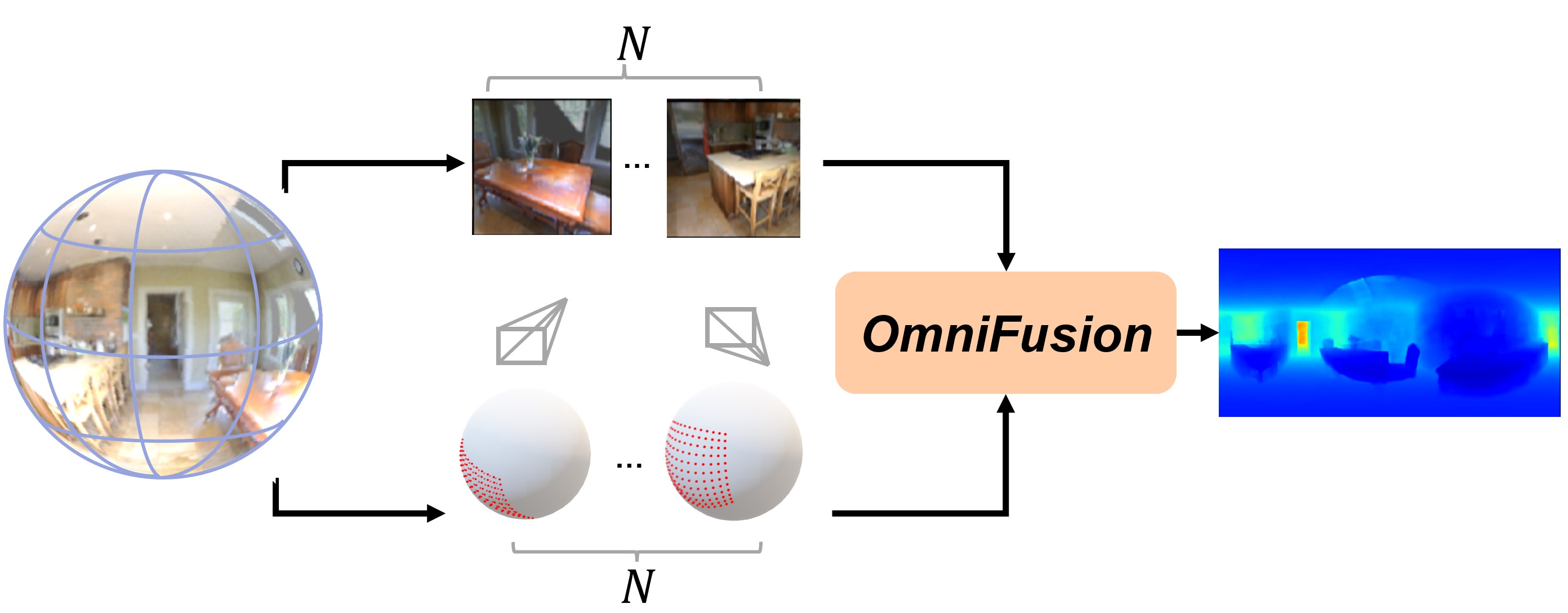
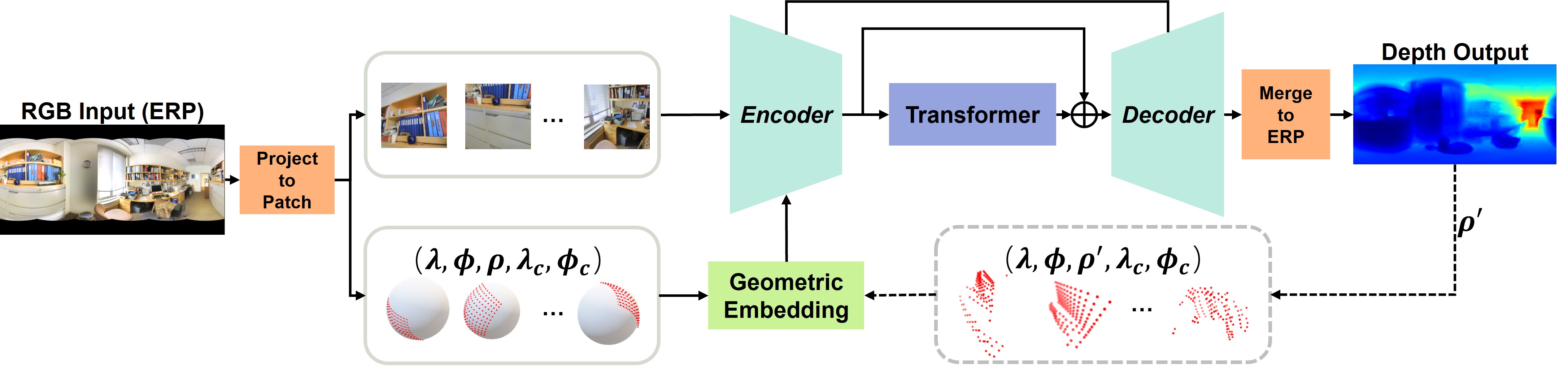
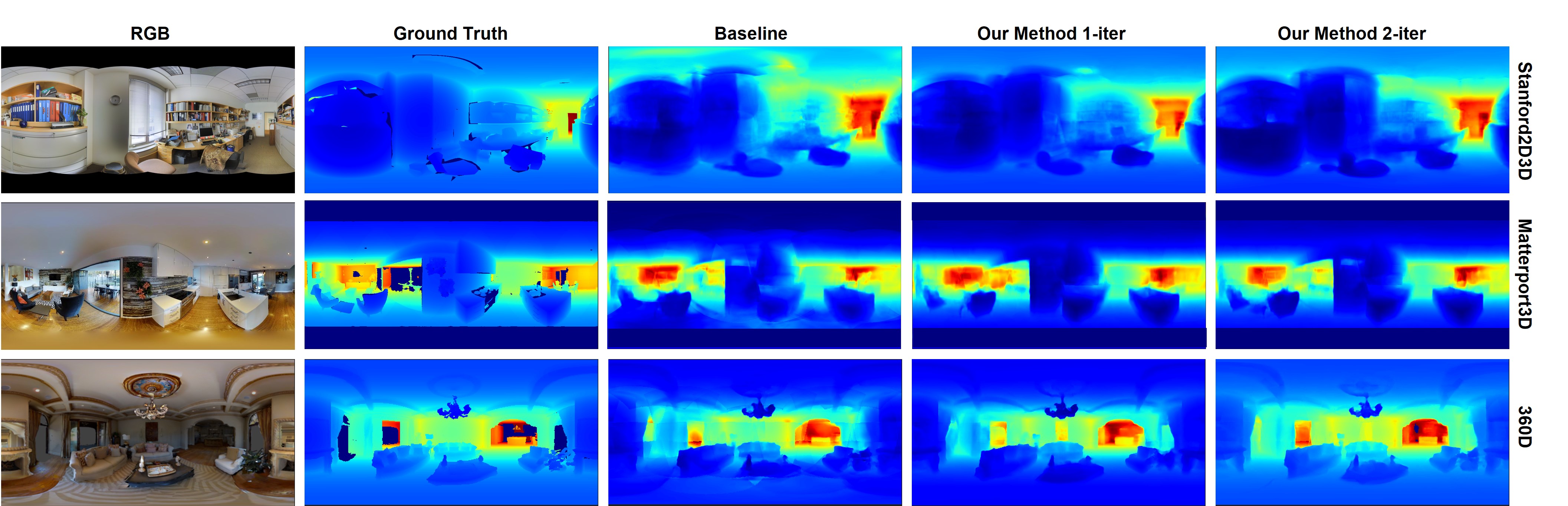
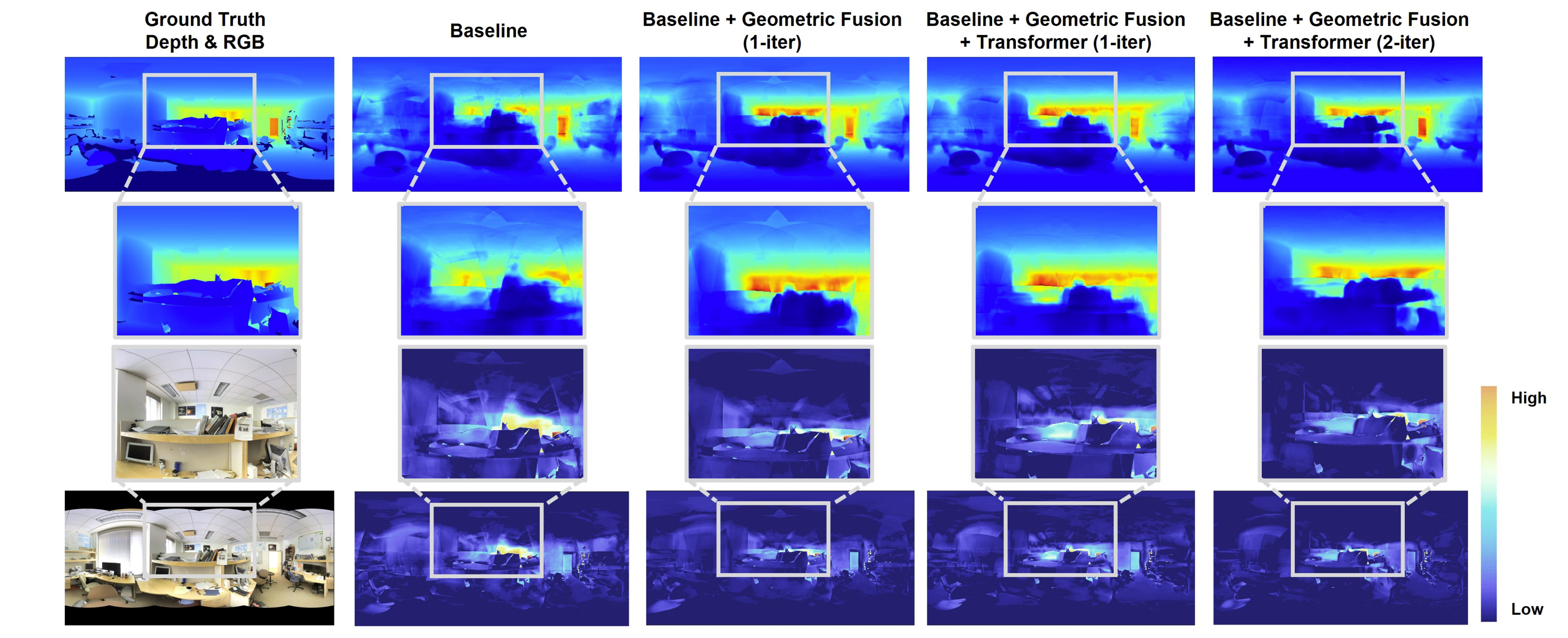
A well-known challenge in applying deep-learning methods to omnidirectional images is spherical distortion. In dense regression tasks such as depth estimation, where structural details are required, using a vanilla CNN layer on the distorted 360 image results in undesired information loss. In this paper, we propose a 360 monocular depth estimation pipeline, OmniFusion, to tackle the spherical distortion issue. Our pipeline transforms a 360 image into less-distorted perspective patches (i.e. tangent images) to obtain patch-wise predictions via CNN, and then merge the patch-wise results for final output. To handle the discrepancy between patch-wise predictions which is a major issue affecting the merging quality, we propose a new framework with the following key components. First, we propose a geometry-aware feature fusion mechanism that combines 3D geometric features with 2D image features to compensate for the patch-wise discrepancy. Second, we employ the self-attention-based transformer architecture to conduct a global aggregation of patch-wise information, which further improves the consistency. Last, we introduce an iterative depth refinement mechanism, to further refine the estimated depth based on the more accurate geometric features. Experiments show that our method greatly mitigates the distortion issue, and achieves state-of-the-art performances on several 360 monocular depth estimation benchmark datasets.
Cite
@inproceedings{li2022omnifusion,
title={Omnifusion: 360 monocular depth estimation via geometry-aware fusion},
author={Li, Yuyan and Guo, Yuliang and Yan, Zhixin and Huang, Xinyu and Duan, Ye and Ren, Liu},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={2801--2810},
year={2022}
}